- Published on
No shortage of ways Data can go wrong when it comes to Machine Learning
- Authors

- Name
- AbnAsia.org
- @steven_n_t
There are no magic tricks to avoid those, but there are ways to mitigate them to some degree.
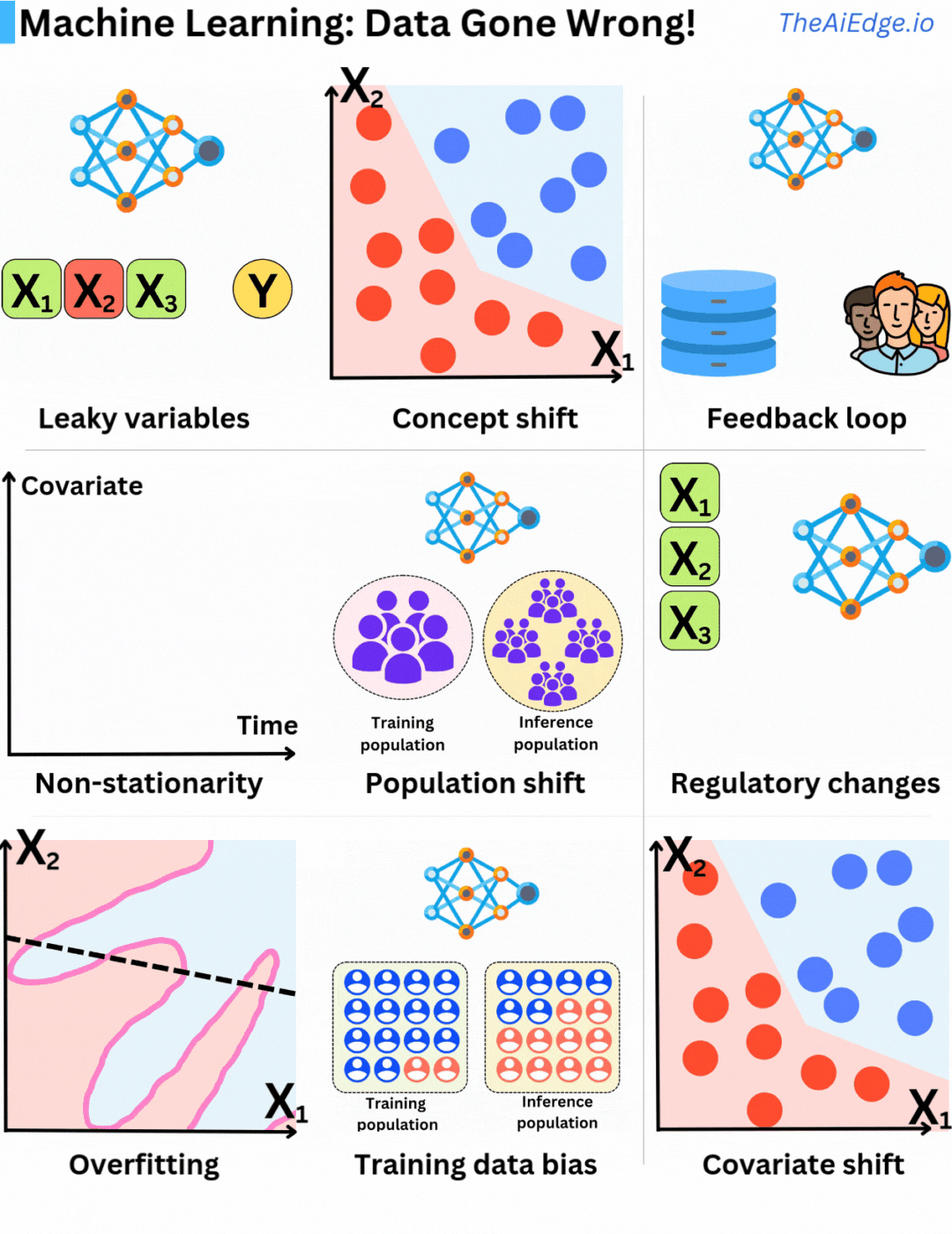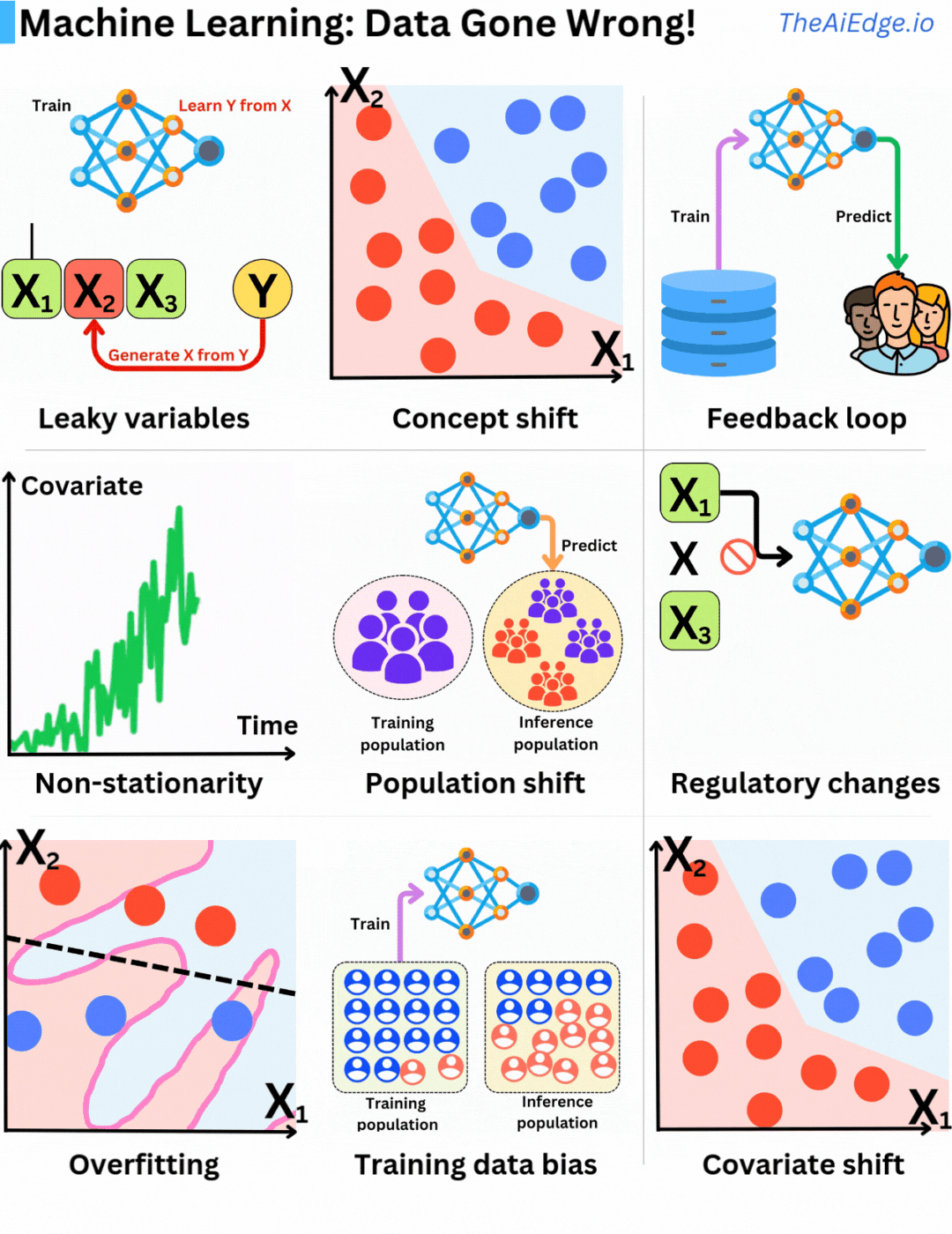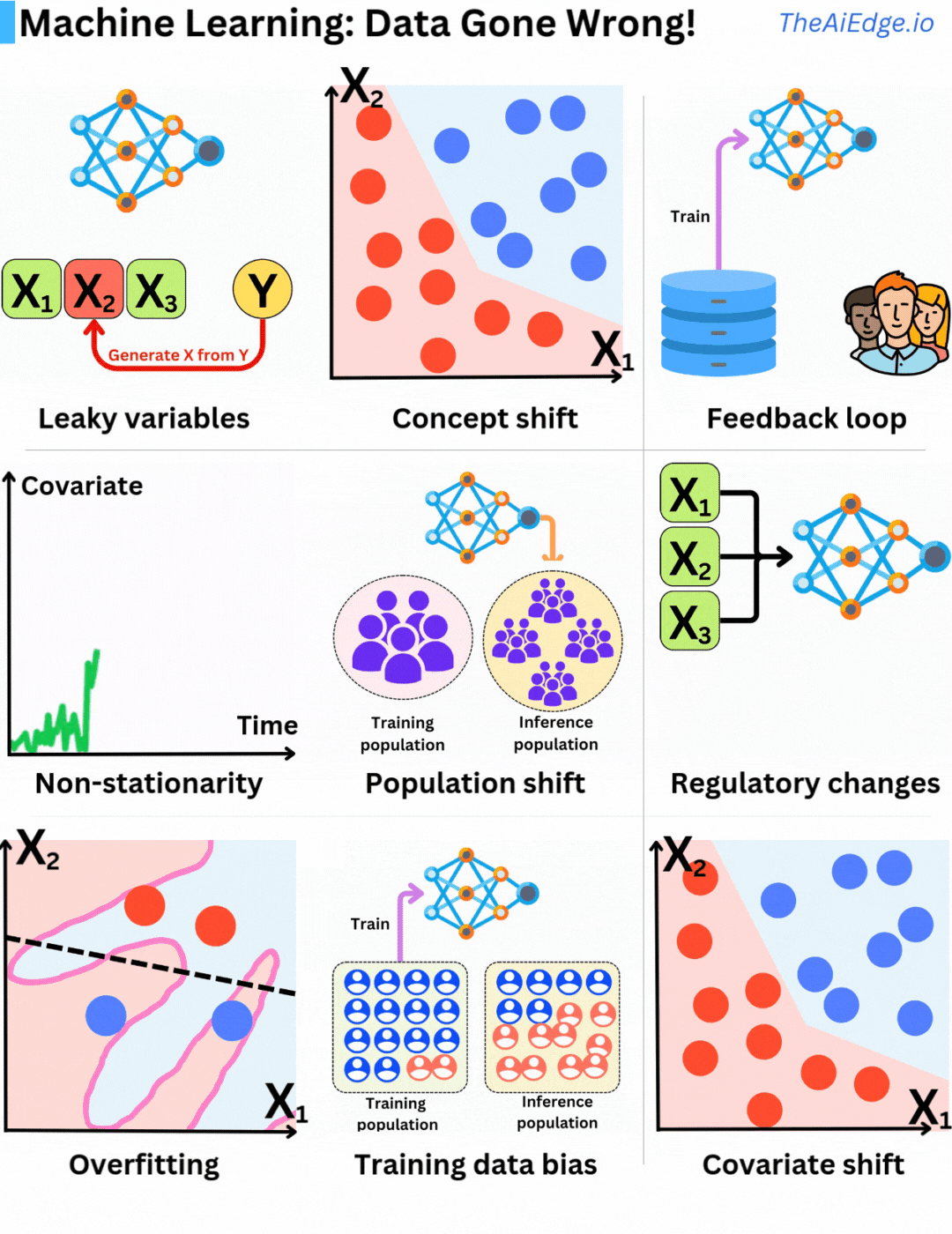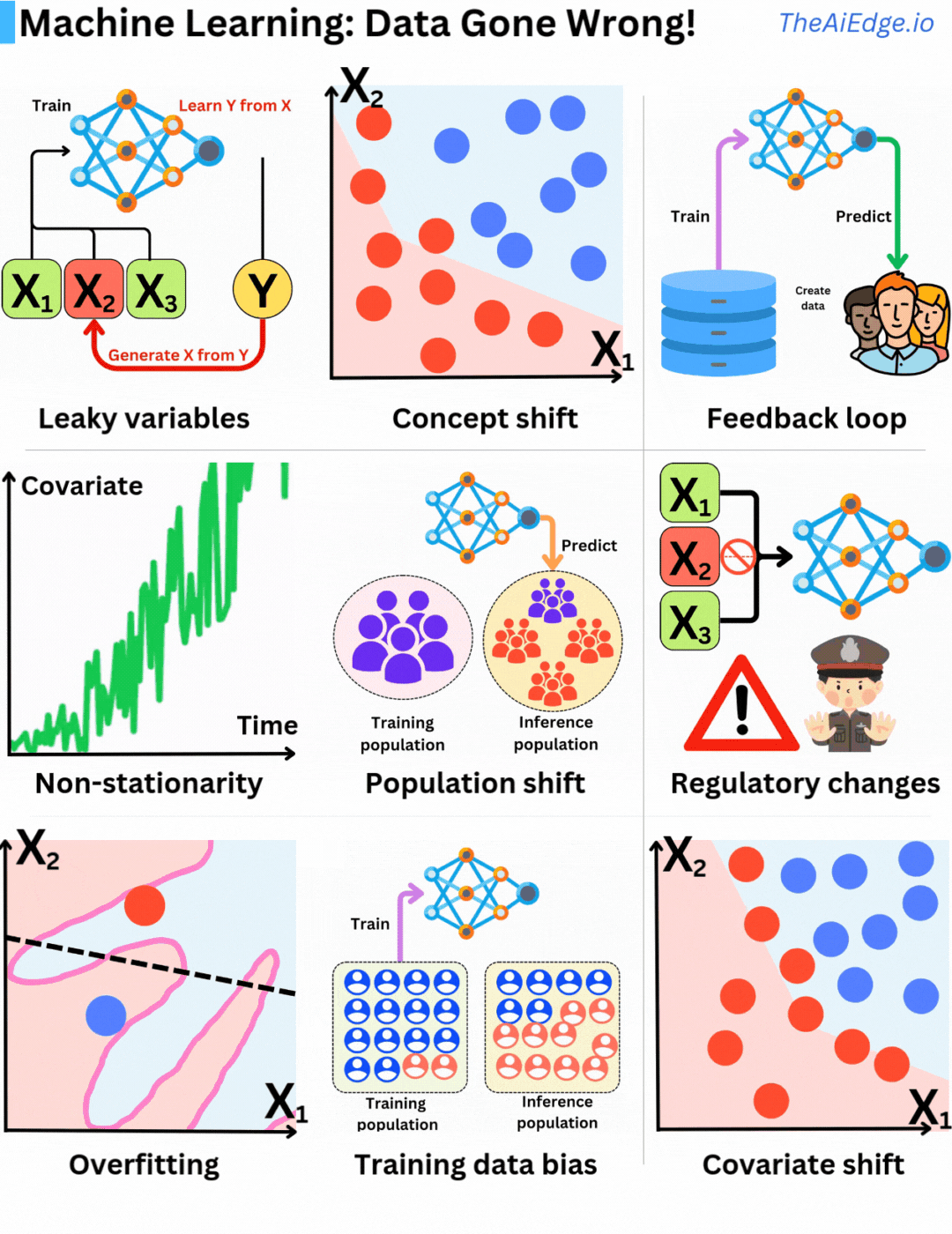
There is definitively no shortage of ways Data can go wrong when it comes to Machine Learning! There are no magic tricks to avoid those, but there are ways to mitigate them to some degree.
Leaky variables are when you are using information you could not have known at the time of prediction in your training data. In a sense, you are including what you are trying to predict as part of your feature set, which leads to seemingly overperforming models.
Concept drift is when the distribution of the underlying input variables remains the same, but their relationships to the target variable change. That is why it is important to have periodic retraining or continuous training strategies in place.
Feedback loops are when the current model's predictions are used to accumulate future training data. Because of it, it leads to selection bias with future models trained on data that do not represent well production data. That happens a lot in recommender engines! That can actually tend to lead to better models but it also can reinforce mistakes made by previous models.
Stationarity is a fundamental assumption in statistical learning as we assume that samples are identically distributed. If their probability distribution evolves over time (non-stationary), the identical distribution assumption is violated. That is why it is critical to build features that are as stationary as possible. For example dollar amount is not a good feature (because of inflation), but relative dollar changes (Δ) may be better.
Population shift is a typical problem leading to concept shift and non-stationarity. The underlying population used for the model to infer changes over time, and the original training data isn't anymore representative of the current population. Again periodic retraining is a good remedy for this problem.
Regulatory changes are a difficult one! One day, a new data law is voted or the Apple Store changes its privacy policies making capturing a specific feature impossible. Whole companies went bankrupt because they were relying on specific data that Google Play or Apple Store allowed to capture one day, but prevented the next.
Overfitting is obviously the most well-known one, and fortunately, it is the one that every ML engineer is well prepared for! This is when the model does not generalize well to test data because it captures too much of the statistical noise within the training data.
Training data bias is when the sample distribution during training does not represent the production data distribution well, leading to biased models. It is crucial to understand how the bias will affect the inferences.
Covariate shift is when the input feature distribution P(X) changes but not their relation to the target P(Y|X). This may lead to biases in the training data selection process that may result in inaccurate models.
Author
AiUTOMATING PEOPLE, ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA