- Published on
What are Optimizers and why do they even exist?
- Authors

- Name
- AbnAsia.org
- @steven_n_t
We all know that, Optimizers guide the learning process: They adjust parameters to minimize the loss function, helping neural networks learn.
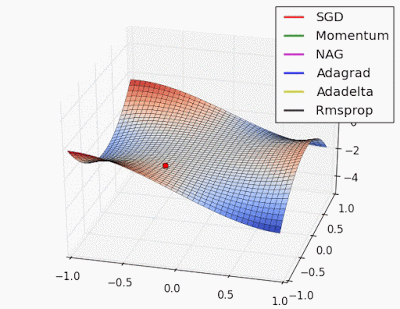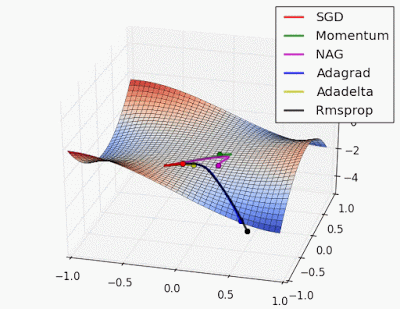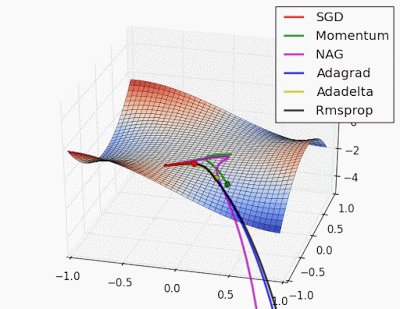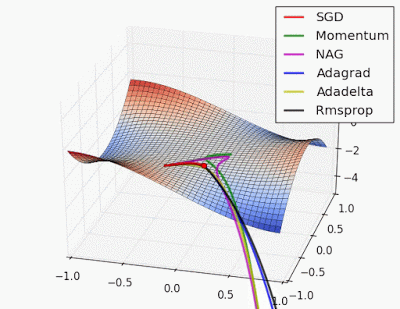
What? Can you explain in simpler terms.😀
Well, Imagine you are on a road trip with your friends and you are lost.
Terrain is hilly and it’s dark. Luckily, your car has a GPS.🚗
Think of optimizers as your car GPS. 🛰️
Just as a GPS guides you to your destination in the quickest or smoothest route possible, optimizers guide the training process towards lower loss values (destination).
A basic optimizer, like simple gradient descent, is similar to driving with a basic route map: it might get you there eventually but could lead to detours (no real time update, road breakdowns etc).
While Adaptive optimizers, like Adam or RMSProp, are like a fancy GPS, adjusting for real-time obstacles and taking efficient paths to reach the destination faster.
Without a GPS, you could spend hours navigating unknown routes. 🚫Similarly, without an optimizer, training a model would be a long and arduous process, struggling to learn from data effectively.
But why so many options?
Okay, let’s first understand what problems Optimizers solve:
1️⃣ Efficiently Searching the Weight Space - Training a neural network means navigating a complex non-convex landscape (hilly terrain) of weights and the goal is to find that combination that minimize loss.
2️⃣ Stable and Reliable Convergence - During training, models can get "stuck" in local minima, or the weights might oscillate without converging. Optimizers help manage these challenges.
But, why so many?
Story starts way way back, initially developed to solve optimisation problems in mathematics.
Gradient Descent (GD) is from mid 19th century ( that long, really? ), then came Stochastic Gradient Descent (SGD) & Mini Batch GD - While effective, they had limitations, particularly around convergence speed and stability on complex data.
To address these issues, researchers developed more sophisticated optimizers that adapt learning rates or use momentum to handle different gradients more effectively.
Then came, Momentum-based Optimizers (like SGD with Momentum) -> Adaptive Optimizers (such as AdaGrad, RMSProp) -> Adam (a combination of momentum and adaptive methods) -> and newer methods (like AdamW, LAMB, and Lion) that tackle specific training challenges.
New optimizers will continue to emerge, each designed to address specific challenges, like training stability, efficiency, or adapting to newer architectures. Some will become mainstream, some will fade, and some will stand the test of time. But their core purpose—guiding the training process efficiently and effectively—remains the same.
Ah. One last thing. When in doubt, just use Adam 😀
Author
Ai Backbone Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA